


What is Dependency Analysis
FossID can provide information on package dependencies and their license information right in the FossID Workbench user interface. Using the Dependency Analysis feature, you can get a better insight into the licenses your software needs to be compliant with. FossID also provides API for the Dependency Analysis so it can be included in your Continuous Integration pipeline. There are two tools that can be used for dependency analysis: FossID-DA or OSS Review Toolkit.
About FossID-DA
Since Workbench 24.3 this is the default tool used by Workbench for dependency analysis. Read more about FossID-DA here.
About OSS Review Toolkit
ORT is licensed under Apache 2.0 License and available from https://oss-review-toolkit.org/. FossID maintains a stable fork at fossidgui/ort along with some additional build and install scripts to improve the user experience with its installation. Since FossID does not come with the ORT pre-installed, you need to review the detailed build and installation instructions under Dependency Analysis Installation.
Usage
Dependency Analysis is available in the context of a scan, i.e. each scan can run the dependency analysis. Note that the FossID scan and the dependency analysis cannot run at the same time for one scan.
Starting the Dependency Analysis
In the Scan view, click the rightmost tab called Dependencies. In the tab, start a new dependency analysis by clicking the ‘Start’ button. Status updates will be continuously reported while the analysis is running.

The analysis will continue running even after you close the browser window. You will receive a message in the FossID messaging interface when the analysis is completed.
Note that the analysis time may be in range from seconds to hours depending on the size of your project, and your server performance and network connectivity. Some files may be created during the analysis in the scan file structure.
Understanding the Results
ORT uses package managers, such as npm, pip, or Maven, to analyze the dependencies and load their information. The identified information depends on your project files that specify the dependencies. These files are for example package.json (for NodeJS) or setup.py (Python/pip). All the identified dependencies are displayed in a table with the following columns:
- Component Name - The name of the package as provided by the package manager.
- Component Version - The version of the package used during the analysis. The version should match the version specified in the project file. However, if the project file specifies the dependencies using dynamic versioning (for example component1 > 1.1 ), the version analyzed will be the one that the package manager deems to be most suitable at the moment of the analysis.
- License - The license(s) of the package as provided by the package manager for the specified version of the package. The text is an SPDX expression of the licenses declared in the package specification.
- Url - Link to the component home page.
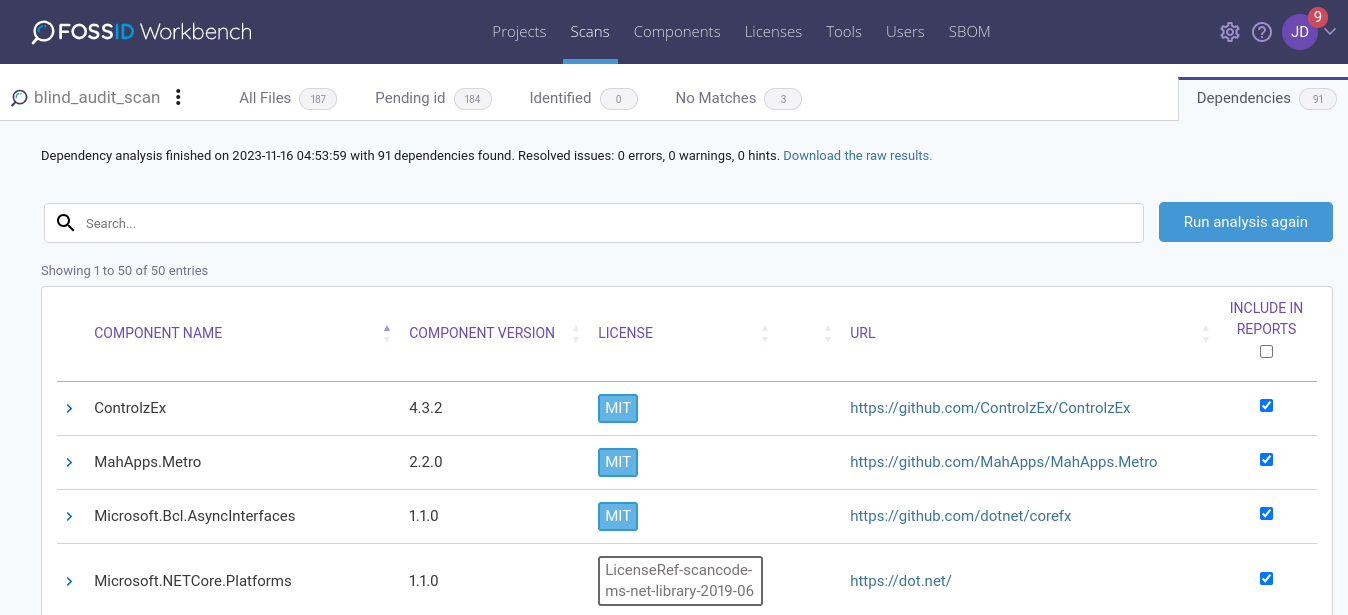
Click the arrow on the left to see more details about each depencency:
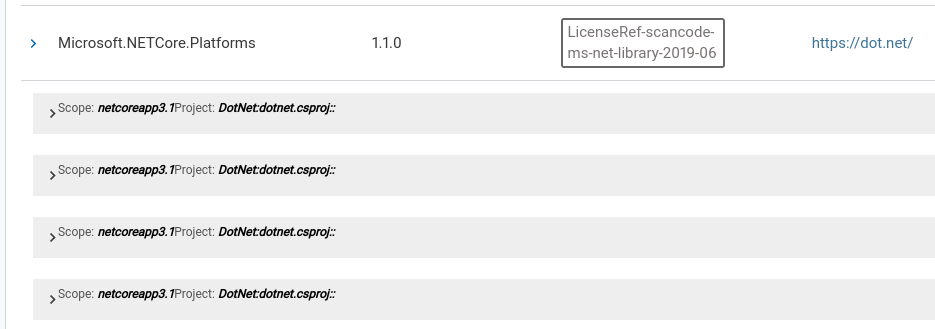
The first level shows what scopes and projects the dependency is in. This is useful when one needs to know whether a package is being distributed or whether it is used just for internal development or testing.
The second level shows the dependency chain for each scope/project combination:
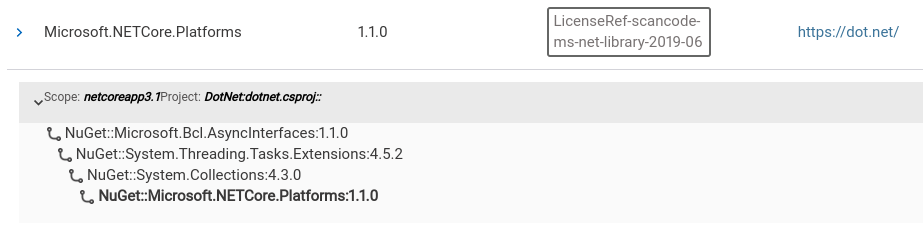
This explains how (through what other dependencies) the dependency got introduced in the project. All of the dependencies found in this chain are listed with license details in the results table.
What is the scope?
During software development, a specific package or library is often needed only for a specific task. Some packages may be needed for compilation, others may be needed for testing, and only some need to be available at runtime thus need to be distributed to the end user.
Many software development frameworks and tools provide the way to specify the type of usage of a dependency package. That is called the ‘scope’. The scope can have different names for different types of projects so it is better to check with the author of the source code to get the right meaning.
Raw Results
Clicking the ‘Download the raw results’ downloads an analyzer-result.json file. This file contains detailed information about the dependencies found, their source, license, and so on. In case of issues with the analysis, the section ‘issues’ of the analyzer-result.json file may contain helpful information on how to improve the analysis.
Reports
The Dependency Analysis is a special section in the Basic report and in the Excel report. Also dependencies are included in SPDX and CycloneDX reports.
API
The Dependency Analysis comes with a set of API functions that allow you to run the analysis on a scan and get the results in a programmatic way. See the Workbench API category in the documentation for more details.
Supported technologies and package managers
The support is currently limited to:
- Bower (JavaScript)
- Bundler (Ruby)
- Cargo (Rust)
- Carthage (iOS / Cocoa)
- CocoaPods
- Composer (PHP)
- Conan (C / C++, experimental as the VCS locations often times do not contain the actual source code)
- Godep (Go)
- DotNet (.NET, with currently some limitations and may require
dotnet-sdk-6.0fornuget-inspectorin some dependencies) - GoMod (Go, experimental as only proxy-based source artifacts but no VCS locations are supported)
- Gradle (Java)
- Maven (Java)
- NPM (Node.js)
- NuGet (.NET, with currently some limitations and may require
dotnet-sdk-6.0fornuget-inspectorin some dependencies) - PIP (Python)
- Pipenv (Python)
- PNPM
- Poetry
- Pub (Dart / Flutter)
- SBT (Scala)
- Stack (Haskell)
- Yarn, Yarn2 (Node.js)
Running the dependency analysis on a project that combines the supported and unsupported technologies will produce incomplete results. For details about setting up ORT and the package managers, see the installation instructions, ORT FAQ and Troubleshooting ORT sections.