


A FossID scan system can be deployed and accessed in a few ways. What parts of the components that neded to be configured is dependent on the type of deployment and how the scan system will be used. In the figure below, we see an overview of the FossID components involved to perform a scan.
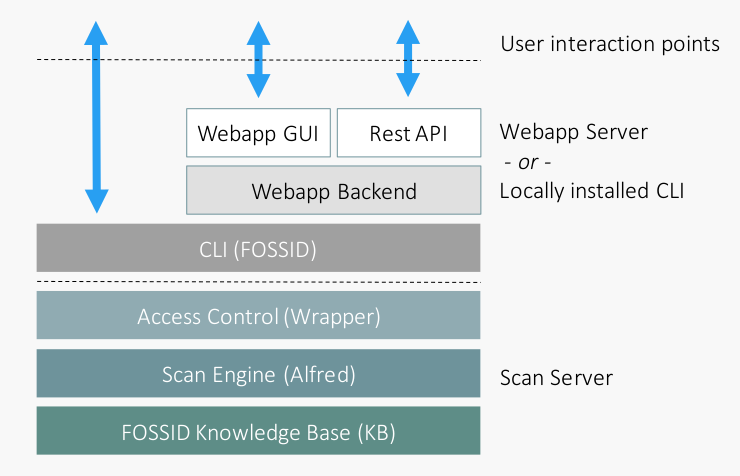
Component description:
- Workbench GUI provides users with a graphical user interface to perform and access scans and other tasks.
- API allows automated interaction with the scan server, useful for e.g. CI integrations.
- Workbench Backend is the information access point for the Workbench GUI and RestAPI.
- CLI (fossid) is a command line interface that interacts with the scan server, it prints scan results on per file level.
- Access Control (wrapper) checks the validity of the scan request and configures the scan accoring to the account settings.
- Scan Engine (alfred) issues scans in accordance with the account settings.
- Knowledge Base (KB) contains scannable access to the >50 million OSS projects that have been harvested by FossID.
The components are typically deployed in two separate server types, Workbench servers that hosts the user interaction points and scan servers that provided scan service to direct CLI users and Workbench users. The deployment types serves as a natural boundry for source code access, see more detailed overview below.
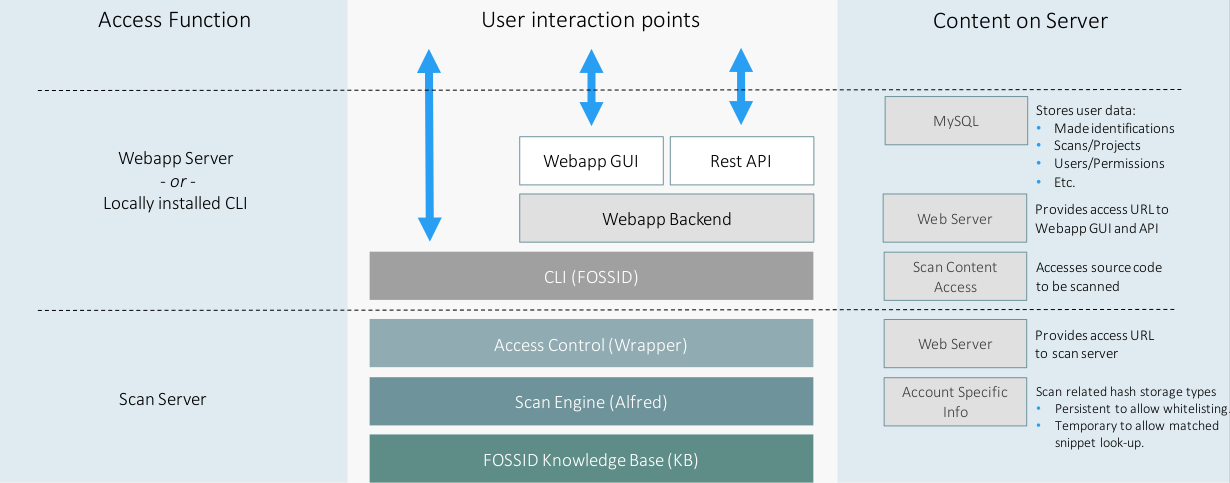
The content on server listed here is a subset of the dependencies that a deployment have, focusing on the items useful to know about to understand how a FossID deployment works.
- MySQL, FossID uses a standard MySQL database to store information, thereby allowing customers to have full access to the stored content if needed.
- Web Server, the type of webserver used is up to the customer. In FossID we use the NginX websever in our test set-ups.
- Scan content access source code access is needed to create the digital signatures used for scanning. If scanning from the Workbench server, it needs to have access to the source code either as uploads or as an accessible file system path.
- Account specific info, this is not a dependency per se, though it is an important aspect of the scan server. During access control, the settings for the request is set on a per account basis, allowing persistent white-listing of content within a project and ability to retrieve found snippets for a period of three weeks (if using the FossID scan server in the cloud). If a snippet needs to be retrived after this three week period, the file must be rescanned.
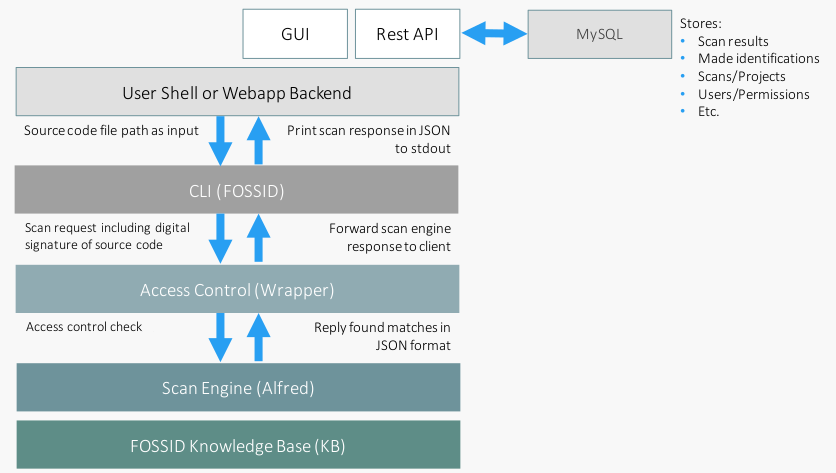
The interaction between the components is can be broken down into the following items:
- Source code, an accessible source code path is provided either as a path to the CLI, GUI or API. Alternatively, the source code can be uploaded into the GUI.
- Digital signatures, is created for each file of the scanned source code. The digital signature is created using an irreversible hashing algorithm, no code is ever sent as part of or can be reconstructed from the digital signature.
- Access control check, if the scan is issued with a valid token, the scan is initiated with the token applicable settings.
- JSON response, all responses are made in JSON format if not explicitly requested otherwise. Scan results or info requests are sent back to the requesting client. In case of a CLI call, it is printed to the stdout of the client shell, if made form teh Workbench, it is collected and grouped in a MySQL database that assists in identification.